Development for AWS: IAM Roles, Keys, Credentials and Deployment
Post originally published on Santander Global T&O.
También disponible en español.
How do we have to use roles in applications developed natively to be deployed on AWS (Amazon Web Services)? In this article, we will talk about development for Amazon AWS, roles, users, keys, and other aspects related to security in AWS.
It will be a very basic introduction to some concepts about the internal workings of AWS permissions, and some not so basic, but always easy to understand and implement.
At Santander, we are committed to a hybrid cloud strategy using Azure and AWS as public clouds and OHE which is our private cloud. Do you want to know how we developed our cloud strategy?
The concepts described here are specific to AWS but can also be applied to other cloud providers such as Azure or Google Cloud.
1. Basic IAM Concepts (Identity and Access Management)
To start off, we will talk about AWS IAM, users, roles and permissions. This is one of the basics when developing applications, and creating them in a secure way. Moreover, it is also one of the hardest things to understand for newcomers.
AWS IAM is the service where you manage users, groups, permissions, etc. I wouldn’t lie if I said that this is the most important service in AWS…
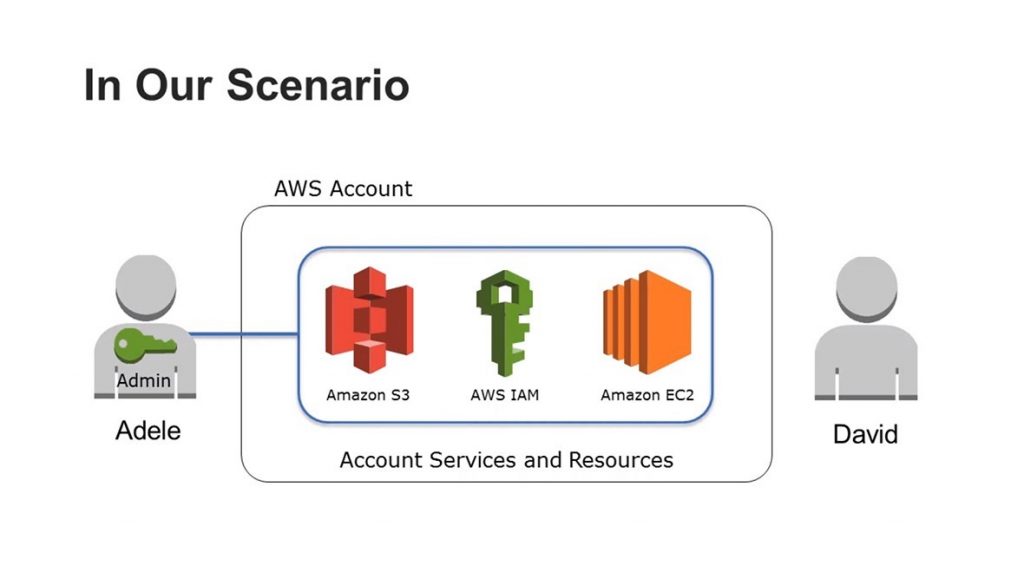
AWS has a lot of services like compute (EC2), object storage (S3), messaging (SQS/SNS), database (RDS), just to name a few. When we want to use or connect to these services, we need a user in AWS. This user has a series of policies attached to it, for example:
{
"Version": "2012-10-17,"
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:*"
],
"Resource": "*"
}
]
}
The previous policy allows us to execute all S3 actions (s3:) on any resource (); for example, we could create an S3 bucket (a file container where you can upload data), but we would not be able to create an EC2 instance (a virtual machine). With policies, we can restrict what a user can and cannot do in AWS.
In spite of that, we can create an S3 bucket from a script, without using the web console? No problem, you can install the AWS CLI (or use other tools like CloudFormation, Terraform or Pulumi) and generate an access key (a pair of an access key id, and a secret access key) and then you could run:
AWS_ACCESS_KEY_ID=ABCD
AWS_SECRET_ACCESS_KEY=EF1234
aws s3 mb s3://mybucket
In this case, the AWS CLI will use the environment variables AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY You could also store these keys manually in the file ~/.aws/credentials or by running AWS configure. As you can see, the CLI (and any other script or program that use the AWS libraries) will try to find these keys using multiple ways. You can do the same thing using the CLI as using Web Console, you are only limited by the permissions of your user. Easy, right?
2. The problem with the keys
Well, easy and not so easy… What would happen if a developer uploads its credentials to a public Git repo by mistake (you wouldn’t be the first nor the last person who did that…)? There are a lot of mad people seeking continuously for this kind of data. If a hacker finds your keys, he would be able to create buckets, upload files, share the contents, etc. That would probably increase your AWS bill, or even worse, access your data and ask for a rescue; there have been cases where the hackers created instances for mining bitcoins.
To avoid this, and save us from the problem of generating keys, rotating, distributing them, and so on. AWS has the concept of role. A role is a set of policies that can be assigned to other AWS resources, so these resources can perform actions without the need of credentials.
For example, we could create a role for an application that uploads data to S3; for this, we may create a role with a policy that only allows access to a specific S3 bucket and nothing else.
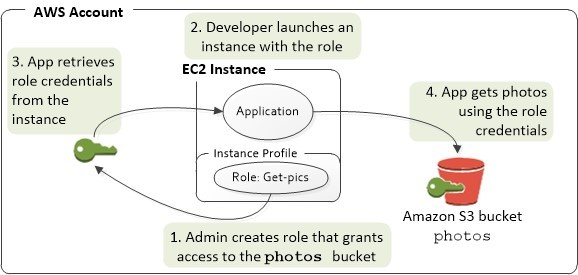
We can deploy this example application in a virtual machine (an EC2 instance), or even better, a container deployed in ECSFargate. But how can the application access the bucket? Well, we would assign the role to the ECS service/task.
3. Credential Sources
When the application initialized the AWS library to upload data to the S3 bucket, it searches for the credentials using this list:
- Credentials set directly in the code
- Environment variables (
AWS_ACCESS_KEY_IDandAWS_SECRET_ACCESS_KEY) - Configuration file (
~/.aws/credentials) - Instance/container temporary credentials
The first 3 options are self-explanatory. But what are those instance/container temporary credentials? Well, when we run an application using, for example, an EC2 instance or a container, we can configure them to use an IAM role.
EC2 and containers contain a metadata service automatically (well, not exactly, but this is true in general); this metadata service provides us information about the AWS environment: the public and private IP address, the AMI we are using, the region, availability zone, etc.
And… the most important for us at this moment, a set of temporary credentials with the permissions assigned to the role that we have attached. Boooom! These temporary credentials are rotated automatically, so we don’t have to worry about if we lose them, because they will be invalid after a short period of time. As said before, this is one of the options used automatically by the AWS libraries, if no other credential source can be found.
This way of assigning permissions to objects using roles is used across all AWS services, for example, in Lambda, for accessing other AWS resources needed by the code; in ECS for launching containers, as it needs to access other AWS resources (for example, ECR, or for creating network interfaces); etc.
4. From local to cloud
The use of roles is the main difference when we deploy the applications in AWS that is different than when we develop locally. But if we know that the AWS libraries automatically try to find the best suitable credentials source, we can forget about it. For example, the following Python snippet:
# https://boto3.amazonaws.com/v1/documentation/api/latest/guide/quickstart.html#usin
g-boto3
import boto3
# Let's use Amazon S3
s3 = boto.resource('s3')
# Print out bucket names
for bucket in s3.buckets.all():
print(bucket.name)
It would run in the developer computer if he has configured his own personal credentials in the file ~/.aws/credentials, but also when deploying in a container in AWS using roles. The same code. No modifications, access keys in the code, roles in the code and also no configuration. Magic!
5. Wrap up
Developers often requires that the DevOps configure a set of keys in the instances, as this is the way they are used to work locally. But this is not necessary, and is a security problem. If we, as AWS experts, or trying to be, teach developers, DevOps, and other teams to focus on security and usability, we all be happier, and our application will be more secure, resilient, etc. That is what we want to achieve, because this will make that the final users will be happy too.

Santander Global T&O is a global company of Santander Group with more than 2,000 employees and based in Madrid, we work to make Santander an open platform for financial services.
Check out the positions we have open here to join this great team and Be Tech! with Santander.